



Most sites deliver regularly-produced content as part of their
architecture. At its simplest, it might just be a blog section through
which company news, updates and outreach are posted. At its best,
however, it’s a carefully pruned source of evergreen SEO traffic and a
lean component of your site indexing strategy.

Most SEOs that have been in the industry for a while would largely agree that overall domain SEO performance can be generalised to be a balance between the total backlink profile of the site (its “Authority”) and the total number of pages indexed on the domain (the total “Domain Sprawl”).
Obviously, this is a massive generalisation. But, in my experience, it is a fundamental axiom for SEO that’s stood the test of time and is a component of SEO that still moves the needle when SEO strategies built around it are executed.
With that in mind, it’s apparent that any content which is indexed (and therefore contributing to domain sprawl) has to pull its own weight or it will drag down the overall performance of the site.
This requirement is the basis of site architecture optimisation but is often ignored in the day-to-day management of a site’s SEO campaign. Why? Freshly generated content will always be a crucial part of a good domain architecture, but without a regular review of effectiveness, it can simply drift into long-term domain sprawl with little traffic return to show for it.
There are a couple of neat, quick search tricks we can use to find older content that’s failing to deliver return for its indexed SEO value. Let’s walk through them.
Let’s take a look at the BBC to see how this might throw up some opportunities to prune.
Chaining our operators and setting an earliest first index date of two years ago, we can dig out some cruft pretty easily:
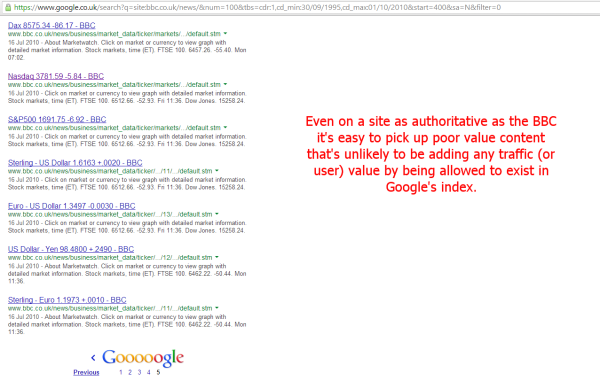
I think we can agree that content like this and this are not necessarily of the highest value in the index (though they do now have extra backlink value, of course!). Though not necessarily “out of date” — their contained data is dynamically updated by the BBC — their indexing makes them landing pages without the surrounding BBC website. This makes for a very poor searcher experience; thus, this content is best cleaned away from the index.
On a side note, we can then quite easily find the BBC’s xml sitemap listing these pages. This strategy isn’t ideal, as it would override any canonicals and is just promoting the indexing of effectively frame pages.
We can take a more extreme view of the indexing date range to dig out some better examples of old content that could well be retired to benefit the domain as a whole. Tweaking the search to set the latest first index date to 2001 hits a goldmine.
By further refining our operators, we can dig out all examples of particular types of content that would do well to be removed from Google’s index. In this example, chaining an intitle operator of “VOTE2001″ with the site operator and setting a comprehensive date range will allow you to hoover up all example URLs that should be canonicalised into more useful content in the same section.

Additionally, if your underlying CMS system is flexible enough, you may be able to use the URL/Content patterns identified using this process to export and redirect all relevant content instead. Just beware that if you use a hard 301 redirect, and you leave link references to the content elsewhere on the site that are likely to be visited by real people, then you would be creating a poor user experience by forcing a redirect on them.
This is why I favour a canonical solution, as only the search engines are “redirected” — this means that for the edge cases where the old content is still relevant to users arriving from elsewhere on the site (like your own internal search function), the content is still accessible. Crucially, your old content is no longer pulling SEO value away from the rest of the domain.
With a site as large, and a history as long, as the BBC, this technique can be dramatically influential in improving overall rankings across the board for more relevant terms with tomorrow’s fresh content.
The General SEO Theory
Most SEOs that have been in the industry for a while would largely agree that overall domain SEO performance can be generalised to be a balance between the total backlink profile of the site (its “Authority”) and the total number of pages indexed on the domain (the total “Domain Sprawl”).
Obviously, this is a massive generalisation. But, in my experience, it is a fundamental axiom for SEO that’s stood the test of time and is a component of SEO that still moves the needle when SEO strategies built around it are executed.
With that in mind, it’s apparent that any content which is indexed (and therefore contributing to domain sprawl) has to pull its own weight or it will drag down the overall performance of the site.
This requirement is the basis of site architecture optimisation but is often ignored in the day-to-day management of a site’s SEO campaign. Why? Freshly generated content will always be a crucial part of a good domain architecture, but without a regular review of effectiveness, it can simply drift into long-term domain sprawl with little traffic return to show for it.
There are a couple of neat, quick search tricks we can use to find older content that’s failing to deliver return for its indexed SEO value. Let’s walk through them.
Finding The Old “Fresh”
Given that we’re in the business of reducing our indexed pages, the first tool you should turn to is Google. Using a combination of site index operators and indexed date range tools provided by Google, we can get a list of indexed URLs within any range of dates we’d like.Let’s take a look at the BBC to see how this might throw up some opportunities to prune.
Chaining our operators and setting an earliest first index date of two years ago, we can dig out some cruft pretty easily:
I think we can agree that content like this and this are not necessarily of the highest value in the index (though they do now have extra backlink value, of course!). Though not necessarily “out of date” — their contained data is dynamically updated by the BBC — their indexing makes them landing pages without the surrounding BBC website. This makes for a very poor searcher experience; thus, this content is best cleaned away from the index.
On a side note, we can then quite easily find the BBC’s xml sitemap listing these pages. This strategy isn’t ideal, as it would override any canonicals and is just promoting the indexing of effectively frame pages.
We can take a more extreme view of the indexing date range to dig out some better examples of old content that could well be retired to benefit the domain as a whole. Tweaking the search to set the latest first index date to 2001 hits a goldmine.
By further refining our operators, we can dig out all examples of particular types of content that would do well to be removed from Google’s index. In this example, chaining an intitle operator of “VOTE2001″ with the site operator and setting a comprehensive date range will allow you to hoover up all example URLs that should be canonicalised into more useful content in the same section.
Additionally, if your underlying CMS system is flexible enough, you may be able to use the URL/Content patterns identified using this process to export and redirect all relevant content instead. Just beware that if you use a hard 301 redirect, and you leave link references to the content elsewhere on the site that are likely to be visited by real people, then you would be creating a poor user experience by forcing a redirect on them.
This is why I favour a canonical solution, as only the search engines are “redirected” — this means that for the edge cases where the old content is still relevant to users arriving from elsewhere on the site (like your own internal search function), the content is still accessible. Crucially, your old content is no longer pulling SEO value away from the rest of the domain.
With a site as large, and a history as long, as the BBC, this technique can be dramatically influential in improving overall rankings across the board for more relevant terms with tomorrow’s fresh content.
No comments:
Post a Comment